开源--Prometheus
前言
Prometheus是CNCF的一个开源项目,Google BorgMon监控系统的开源版本,是一个系统和服务的监控系统。周期性采集metrics指标,匹配规则和展示结果,以及触发某些条件的告警发送。
特点
Prometheus主要区别于其他监控系统的特点是:
多维度数据模型(时序数据是由指标名字和kv结构的维度定义)
灵活的查询语言(PromQL)
不依赖分布式存储。每个server是一个自治的节点。
通过HTTP拉取收集时序数据,同时提供push gateway供用户主动推送数据,主要用于短生命周期的job。
通过静态配置或服务发现来发现目标对象
支持多种多样的出图和展示方式,例如自带的Web UI和Grafana等。
支持水平扩容
架构
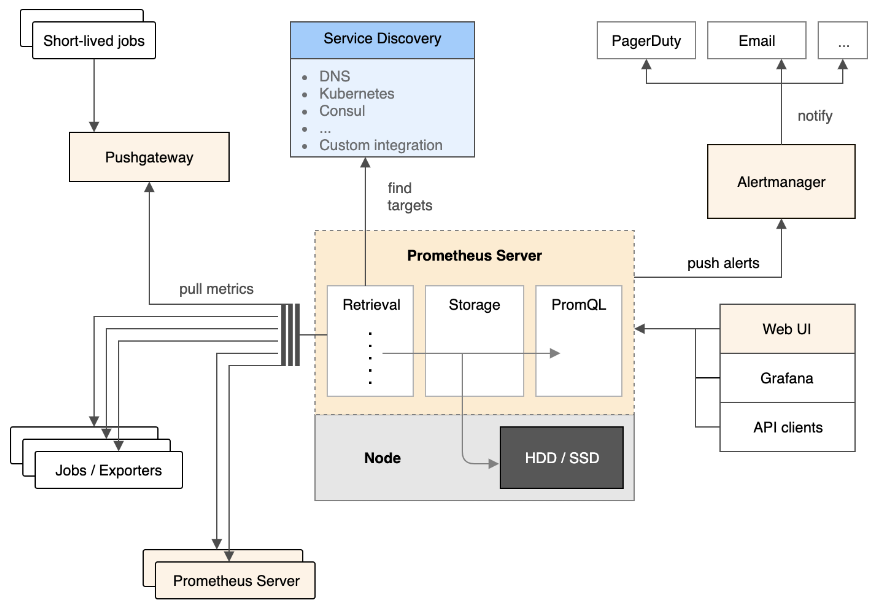
组件
Prometheus生态系统由多个组件组成,其中大部分是可选的组件。
Prometheus Server 负责收集和存储时序数据。提供PromQL查询语言的支持。
Pushgateway 支持短生命周期的任务推送结果数据。
Exporter 采集组件的总称,是Prometheus生态系统中的Agent。
Altermanager 处理告警。
客户端SDK 官方提供的SDK支持的语言由go,java,python等多种语言。
绝大部分Prometheus的组件都是用golang编写,使得Prometheus 组件容易编译和部署。(二进制没有依赖)
工作流程
从架构图中可以看出,Prometheus Server 周期性的拉取从配置文件或者服务发现获取到的目标数据,每个目标需要通过HTTP接口暴露数据。Prometheus Server通过一定的规则汇总和记录时序数据到本地数据库。将符合检测条件的告警数据推送给Altermanager,Altermanager通过配置的通知方式发送告警。Web UI 或者Grafana通过PromQL查询Prometheus Server中的数据绘图展示。
适用的场景
Prometheus在记录纯数字的时序数据方面表现得非常好。既适用于机器的性能数据,也适用于服务的监控数据。对于微服务,Prometheus的多维度收集和查询语言也是非常强大。
不适用的场景
Promethus的价值在于它的可靠性。Prometheus不适用于对统计或分析数据100%准确要求的场景。
部署实战
下面我会通过Docker Compose的方式部署整个Prometheus监控系统和Grafana展示数据。如果对Docker Compose还不熟悉的朋友,可以先查看我之前的介绍文章。
Prometheus的docker-compose.yml基于github的开源仓库修改。docker-compose.yml内容如下:
version: '3.1'
volumes:
prometheus_data: {}
grafana_data: {}
services:
prometheus:
image: prom/prometheus:v2.1.0
volumes:
- ./prometheus/:/etc/prometheus/
- prometheus_data:/prometheus
command:
- '--config.file=/etc/prometheus/prometheus.yml'
- '--storage.tsdb.path=/prometheus'
- '--web.console.libraries=/usr/share/prometheus/console_libraries'
- '--web.console.templates=/usr/share/prometheus/consoles'
ports:
- 9090:9090
restart: always
node-exporter:
image: prom/node-exporter
volumes:
- /proc:/host/proc:ro
- /sys:/host/sys:ro
- /:/rootfs:ro
command:
- '--path.procfs=/host/proc'
- '--path.sysfs=/host/sys'
- --collector.filesystem.ignored-mount-points
- "^/(sys|proc|dev|host|etc|rootfs/var/lib/docker/containers|rootfs/var/lib/docker/overlay2|rootfs/run/docker/netns|rootfs/var/lib/docker/aufs)($$|/)"
ports:
- 9100:9100
restart: always
alertmanager:
image: prom/alertmanager
volumes:
- ./alertmanager/:/etc/alertmanager/
ports:
- 9093:9093
restart: always
command:
- '--config.file=/etc/alertmanager/config.yml'
- '--storage.path=/alertmanager'
grafana:
image: grafana/grafana
user: "104"
ports:
- 3000:3000
depends_on:
- prometheus
volumes:
- grafana_data:/var/lib/grafana
- ./grafana/provisioning/:/etc/grafana/provisioning/
env_file:
- ./grafana/config.monitoring
restart: always
从上面的docker-compose.yml可以看出,将通过Docker Compose部署Prometheus Server,Altermanager,Grafana,和node exporter。其中node exporter负责采集机器的基础性能数据,例如CPU,MEM,DISK等等,通过暴露HTTP接口供Prometheus Server拉取数据做数据存储和清洗。Grafana负责数据的展示。Prometheus通过配置文件静态配置获取node exporter的地址:
$ cat prometheus.yml
# my global config
global:
scrape_interval: 15s # By default, scrape targets every seconds.
evaluation_interval: 15s # By default, scrape targets every seconds.
# scrape_timeout is set to the global default (10s).
# Attach these labels to any time series or alerts when communicating with
# external systems (federation, remote storage, Alertmanager).
external_labels:
monitor: 'my-project'
# Load and evaluate rules in this file every 'evaluation_interval' seconds.
rule_files:
- 'alert.rules'
# - "first.rules"
# - "second.rules"
# alert
alerting:
alertmanagers:
- scheme: http
static_configs:
- targets:
- "alertmanager:9093"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: 'prometheus'
# Override the global default and scrape targets from this job every seconds.
scrape_interval: 5s
static_configs:
- targets: ['localhost:9090']
- job_name: 'node-exporter'
# Override the global default and scrape targets from this job every seconds.
scrape_interval: 5s
static_configs:
- targets: ['node-exporter:9100']
其中40-45行是node-exporter的抓取地址和周期配置。因为Docker Compose会自动做服务地址解析,所以这里可以直接用node-exporter:9100作为地址。
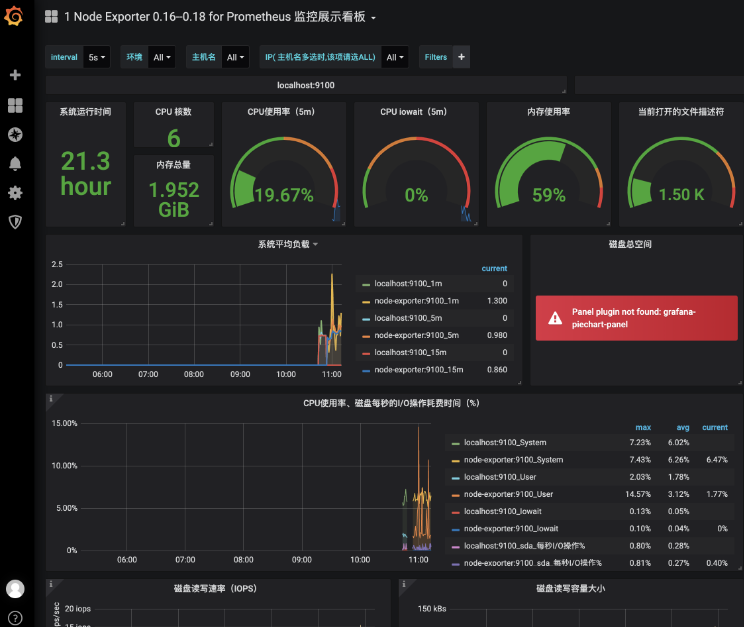
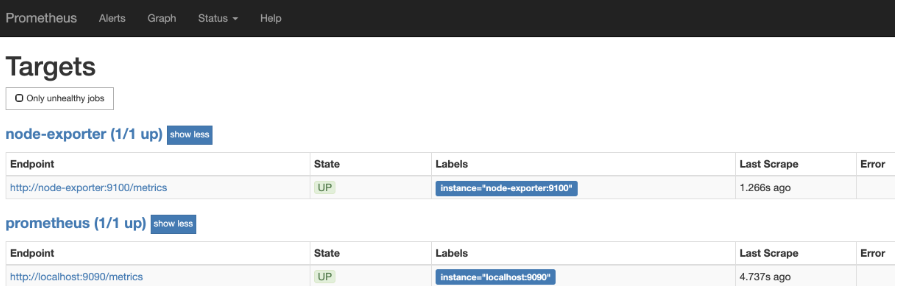
通过Prometheus 9090端口可以查看到要采集的目标列表信息:
通过Grafana可以查看到node exporter采集上来的数据展示,其中Grafana用的看板模板是https://grafana.com/dashboards/8919